
Deep coding: are Cloud ML and Microsoft DeepCoder the first step toward automated coding?
Today the “deep” is fashionable: we have “deep” learning, “deep” vision, “deep” writing … so why not deep coding? Developing artificial intelligence software today can be a long process, so why not to automate coding? Developing machines that can develop themselves with deep coding is the last frontier of automation, perhaps the definitive one.
This is how Sundar Pichai debuted on May 17th, presenting Cloud Auto ML at the Google I/O keynotes 2017:
“Designing better machine models today is really time-consuming. We wanted to be possible for hundreds of thousands of developers to use learning machine. Neural nets to better neural nets. We call this approach Auto ML, it’s learning to learn. “
In the end, developing neural networks is often tedious, so why not let another neural network do the dirty work?
So Google presented Cloud Auto ML, its new AI-As-A-Service paradigm.
Cloud Auto ML

The idea behind this project is to lift the developers from the “dirty work” of configuration and calibration, delegating everything to … neural networks. This dirty work today takes most of the time: it consists mostly of trials and errors, trying out with some algorithms and parameters, tuning them where necessary, or even starting over from scratch.

The system runs thousands of simulations to determine which areas of the code can be improved, makes the changes and continues like this until it reaches the goal.
We could consider it a beautiful representation of the infinite monkey theorem, according to which a monkey pressing random keys on a typewriter, given an infinitely long time, sooner or later will be able to compose any given text. But, instead of a monkey writing Romeo and Juliet on a typewriter, the artificial intelligence produced by Google is able to replicate its own coding. And it manages to do in hours, or even minutes, what the best human developers do in weeks or months.

For example, the GoogleNet architecture (see above) required many years of experimentation and refinement. However, AutoML was able to explore a space of 1010 combinations of network models, managing to propose working solutions in a short time. AutoML came out with solutions that could mitigate the problem of vanishing gradient, well known to those who work with Deep Learning. Perhaps the disturbing part is that not only its solutions were able to solve complex problems, but it did it through “tricks” that were habitually rejected by humans as not very useful.
AutoML is a system of adversarial networks (Generative Adversarial Networks, already introduced here): a “generator” neural network proposes an architecture model, which can be trained and evaluated in a particular task. The feedback is then used to inform the generator on how to improve the next model. The process is repeated thousands of times, generating new architectures, testing them and returning feedback to the generator. Eventually, the generator learns to assign higher probabilities to areas of architectural research space that get better, and lower results to types of architectures that achieve lower results.
Just to give an idea of the kind of architectures that result, an example is presented based on the prediction of the next word in the Penn Treebank.
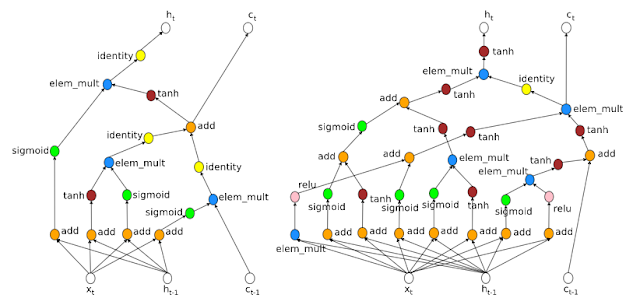
This approach can also help you understand why these types of architectures work so well. The architecture on the right has many channels so the gradient can flow backward, which could help explain why LSTM recursive networks work better than standard recursive networks.
Auto ML (for now only in the field of computer vision) is offered by Google on its cloud platform, with interesting features such as:
- Transfer learning, or the ability to generalize using what it learned through training on a dataset, transferring it to a different dataset.
- Automated optimization, exploiting different techniques already implemented on the platform.
- Image labeling, that is a labeling and “cleaning” service performed by humans, to guarantee the customers quality data to train their own models.
In time, the service will cover all areas of the IA in the cloud, with the option to code using the current Google services as blocks.
DeepCoder

Already back in 2015 MIT had developed Prophet, a system able to solve software bugs using parts of code picked from external repositories.
One year later Microsoft and the University of Cambridge presented DeepCoder at ICLR. Its purpose was to develop programs able to be consistent with simple (for now) mathematical problems based on supplied input-output examples. In other words, “build me a program that can generate these solutions from these inputs”. Specifically, this approach is called IPS (Inductive Program Synthesis), or synthesis of programs via induction.
“All of a sudden people could be so much more productive. They could build systems that [could be] impossible to build before. The potential for automation that this kind of technology offers could really signify an enormous [reduction] in the amount of effort it takes to produce code.”
Similarly to “Jeopardy!” game, the neural network was trained to predict the properties of a program that could have generated the supplied outputs. The results of the predictions are used to improve the search techniques of the system using the various programming languages available in the repositories it could access. Finally, the selected parts were assembled using a domain-specific language (DSL).
The results showed an order of magnitude speedup over standard program synthesis techniques, which makes this approach feasible for solving problems of similar difficulty as the simplest problems that appear on programming competition websites.
“Ultimately the approach could allow non-coders to simply describe an idea for a program and let the system build it” says Marc Brockschmidt, one of the creators of DeepCoder at Microsoft Research in Cambridge.
It is not about “stealing” code around, as some article reported, but an actual creative synthesis process. After all, it is not unusual for a human developer to copy/paste with some (or even no) code changes written by others.
Links
AI learns to write its own code by stealing from other programs
Microsoft’s AI writes code by looting other software
Microsoft’s AI is learning to write code by itself, not steal it
Google’s AI Is Now Creating Its Own AI
SUNDAR PICHAI SEES GOOGLE’S FUTURE IN THE SMARTEST CLOUD
GOOGLE’S LEARNING SOFTWARE LEARNS TO WRITE LEARNING SOFTWARE
Google’s AI can create better machine-learning code than the researchers who made it
DEEPCODER: LEARNING TO WRITE PROGRAMS
P. Schermerhorn et al.: DIARC: A Testbed for Natural Human-Robot Interaction
Cloud AutoML: Making AI accessible to every business
Google hopes to draw more cloud customers by making A.I. easier to use
DeepCoder: Microsoft’s New AI Writes Code For People Who Don’t Know Coding
Using Machine Learning to Explore Neural Network Architecture




