

Proviamo a smitizzare le reti neurali artificiali e a spiegare che spazio occupano nel più vasto ambito del machine learning.
Oggi il machine learning è ovunque, ed è diventato il modo prevalente di declinare il concetto di intelligenza artificiale.
Si tratta di uno dei campi col tasso di innovazione più alto in assoluto, contraddistinto da novità anche radicali che si susseguono senza sosta. Tuttavia i concetti che ne stanno alla base non sono purtroppo semplicissimi da digerire. L’idea è quindi tentare di smitizzare l’argomento e di renderlo il più intuitivo possibile.
Trattandosi di temi non banali, è opportuno fare una premessa: lo scopo di questo articolo non è addentrarsi in dimostrazioni o dettagli matematici. Ogni paragrafo sarà introdotto da una descrizione sintetica del concetto, prima di scendere un po’ più in profondità.
Nella sezione Link ci saranno sufficienti riferimenti per chiunque sia interessato ad approfondire.
Cosa sono le reti neurali? Oltre le definizioni
Wikipedia dà questa definizione:
[…] una rete neurale artificiale (in inglese artificial neural network, abbreviato in ANN o anche come NN) è un modello matematico composto di “neuroni” artificiali, che si ispira a una rete neurale biologica.
Mentre questo è senz’altro vero, purtroppo non aiuta più di tanto a capire di cosa si tratti. Il resto del wiki, pur molto dettagliato, è abbastanza ostico per chi non mastichi già la materia.
Corrispettivo biologico
Le reti neurali artificiali (ANN) sono un algoritmo utilizzato per risolvere problemi di natura complessa non facilmente codificabili, e sono una colonna portante del machine learning come viene inteso oggi.
Sono chiamate “reti neurali” perché il comportamento dei nodi che le compongono ricorda vagamente quello dei neuroni biologici. Un neurone riceve in ingresso segnali da vari altri neuroni tramite connessioni sinaptiche e li integra. Se l’attivazione che ne risulta supera una certa soglia genera un Potenziale d’Azione che si propaga attraverso il suo assone a uno o più neuroni.

Reti Neurali Artificiali in pillole
Possiamo considerare una rete neurale come una scatola nera, con degli input, degli strati intermedi in cui “succedono le cose”, e degli output che costituiscono il risultato finale.
La rete neurale è composta da “unità” chiamate neuroni, arrangiati in strati successivi. Ciascun neurone è tipicamente collegato a tutti i neuroni dello strato successivo tramite connessioni pesate. Una connessione non è altro che un valore numerico (il “peso” appunto), che viene moltiplicato per il valore del neurone collegato.
Ciascun neurone somma i valori pesati di tutti i neuroni ad esso collegati e aggiunge un valore di bias. A questo risultato viene applicata una “funzione di attivazione“, che non fa altro che trasformare matematicamente il valore prima di passarlo allo strato successivo.
In questo modo i valori di input vengono propagati attraverso la rete fino ai neuroni di output, che è praticamente tutto quello che una rete neurale fa. Il succo di tutto è regolare pesi e bias in modo da arrivare ad ottenere il risultato voluto. Per questo ci sono diverse tecniche, come ad esempio il machine learning.
Reti Neurali Artificiali più in dettaglio
Una rete neurale può essere immaginata come composta di diversi “layer” (strati) di nodi, ciascuno dei quali è collegato ai nodi del layer successivo.

Tutte le reti neurali sono composte da almeno tre strati:
- Un input layer, ovvero i dati di ingresso
- Uno o più hidden layer, dove avviene l’elaborazione vera e propria.
- Un output layer, contenente il risultato finale.
Come detto sopra, i nodi sono connessi a tutti[1] i nodi del layer successivo, e nell’algoritmo queste connessioni vengono “pesate” tramite fattori moltiplicativi, che rappresentano la “forza” della connessione stessa.
Come per i neuroni biologici, i nodi delle ANN integrano i segnali in ingresso secondo una apposita funzione (ci torneremo più avanti). Se il valore di questa operazione supera la soglia prevista, il nodo sllecitato trasmette questo valore al layer successivo, altrimenti il valore trasmesso sarà zero.
Qui sotto alcuni valori a titolo di esempio, per chiarire il concetto. Vediamo che il layer di input ha due nodi, X1 e X2, il layer nascosto è costituito dai nodi a1 e a2, mentre O è il nodo di output.

Ciascun nodo del secondo layer sommerà il segnale proveniente da ciascun nodo di input, moltiplicato per il “peso”. Il principio è identico per il nodo di output. Le connessioni w1 e y1 sono quelle uscenti dal nodo X1, mentre w2 e y2 sono quelle uscenti da X2.
Proviamo ad attribuire dei valori, come nella figura sotto. I nodi “nascosti” a1 e a2 riceveranno in ingresso la somma dei nodi X1 e X2, “pesati” dalle connessioni. Quindi il valore ricevuto da a1 sarà uguale a (X1*w1+b1) + (X2*w2+b2), ovvero 1*1 + 0.5*0.5+2 = 3.25, mentre con lo stesso principio il valore ricevuto da a2 sarà -0.3.
A questi valori si applicherà la funzione di attivazione (ci torneremo, per ora prendete per buono), che nel caso di a1 lascerà il valore invariato, mentre per a2 ritornerà zero. Dal layer nascosto quindi usciranno i valori 3.45 e 0, che verranno poi moltiplicati rispettivamente per 2 e -1.25 prima di venire integrati nel nodo di uscita.
Lo stesso principio si applica al nodo di uscita, che riceverà quindi un totale di 6.5, che viene trasformato in 1 dalla funzione di attivazione.
Perché una funzione di attivazione?
Nei neuroni biologici il potenziale d’azione viene trasmesso integralmente una volta che la differenza di potenziale alle membrane supera una certa soglia. In un certo senso è così anche per i neuroni “artificiali”. Solo che il comportamento della risposta viene adattato a seconda delle necessità, ed è determinato dalla funzione di attivazione.
A questo punto ci si potrebbe chiedere perché applicare una funzione di attivazione. Non si potrebbe semplicemente propagare i valori attraverso la rete neurale così come sono?
Funzione di attivazione in pillole
Una rete neurale senza funzione di attivazione equivale semplicemente a un modello di regressione[2], ovvero cerca di approssimare la distribuzione dei dati con una retta (vedi sotto).
In questo esempio si può notare come la retta rappresenti la distribuzione in modo abbastanza impreciso. Con questo modello praticamente ogni layer si comporterebbe allo stesso modo del precedente, e 100 layer sarebbero di fatto equivalenti ad averne uno soltanto: il risultato sarebbe sempre lineare.
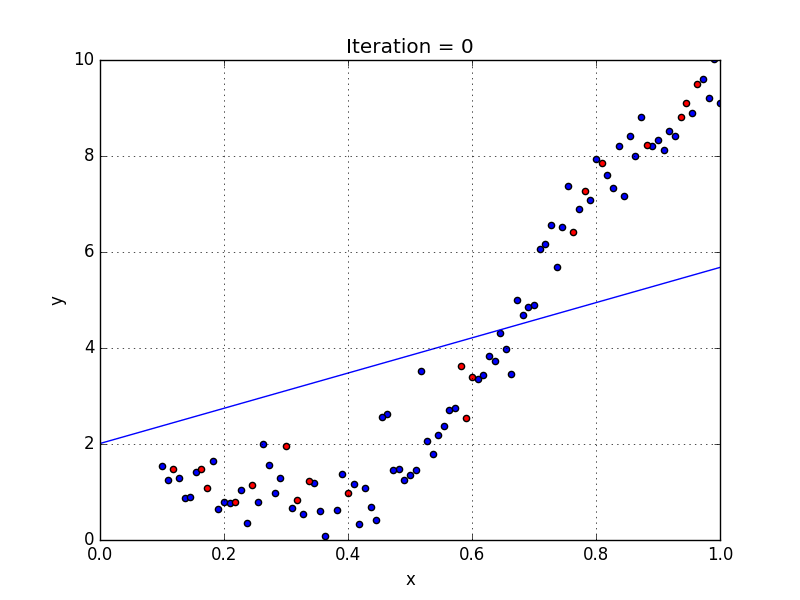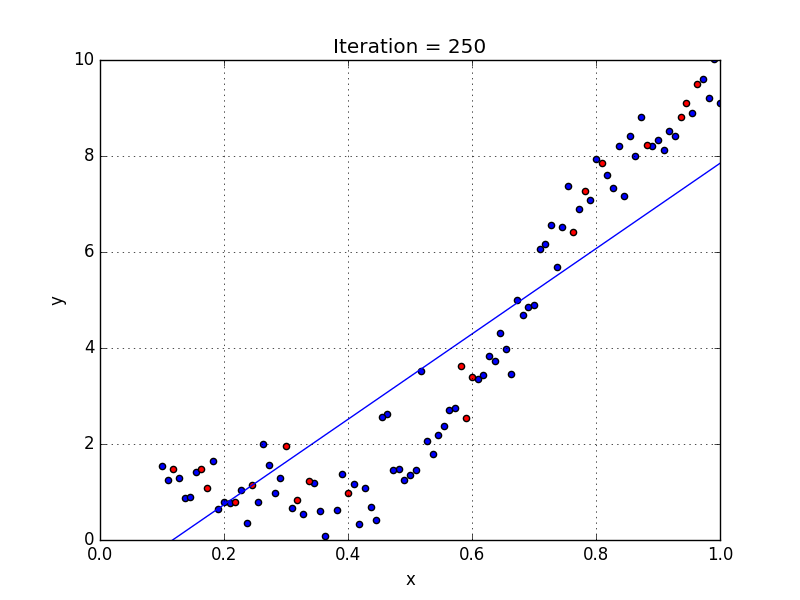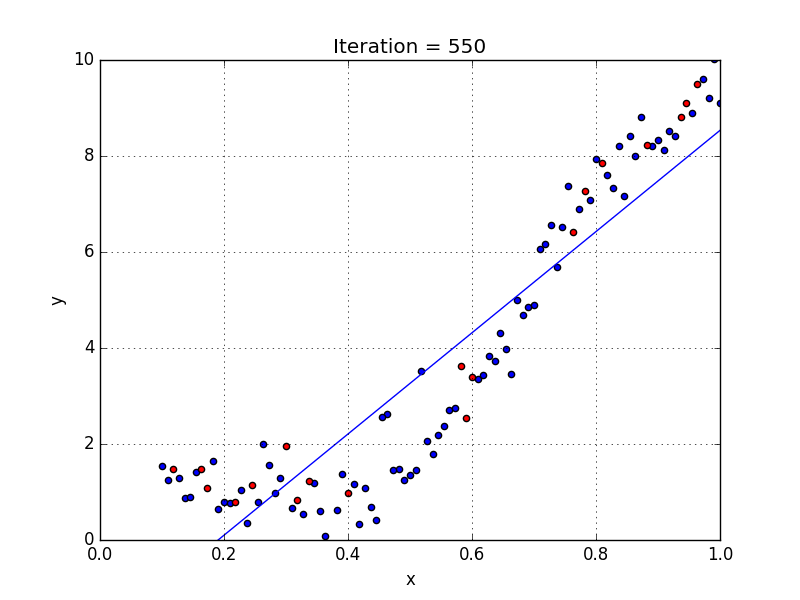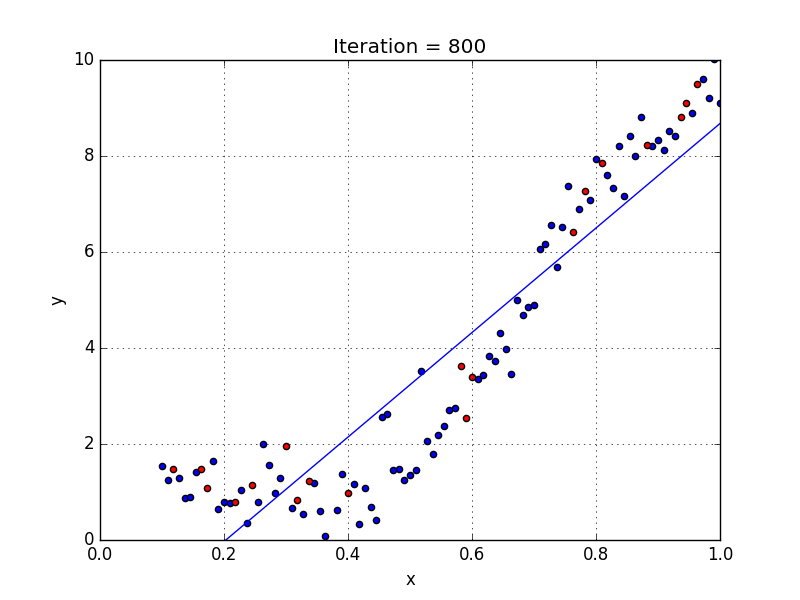
Modello predittivo lineare
Lo scopo delle reti neurali è di essere un Universal Function Approximator, ovvero essere in grado di approssimare qualsiasi funzione, e per fare questo è necessario introdurre un fattore di non linearità, da qui la funzione di attivazione.
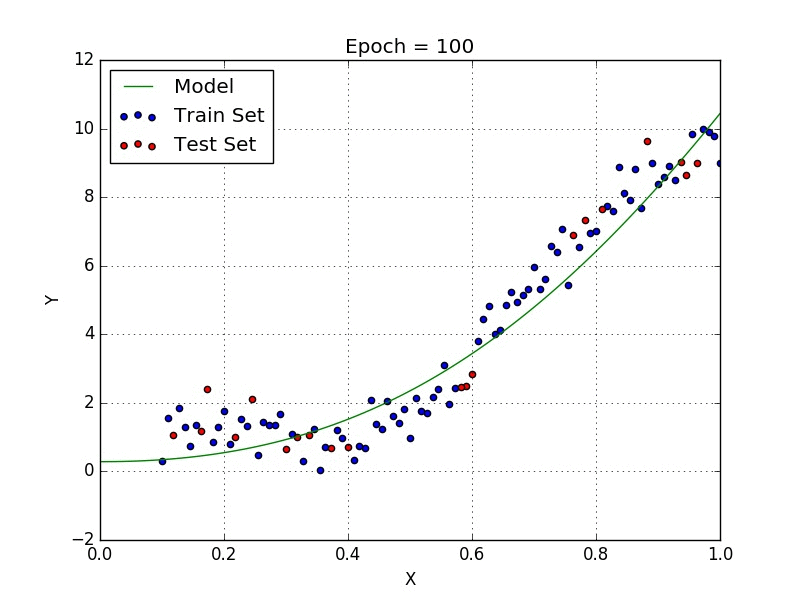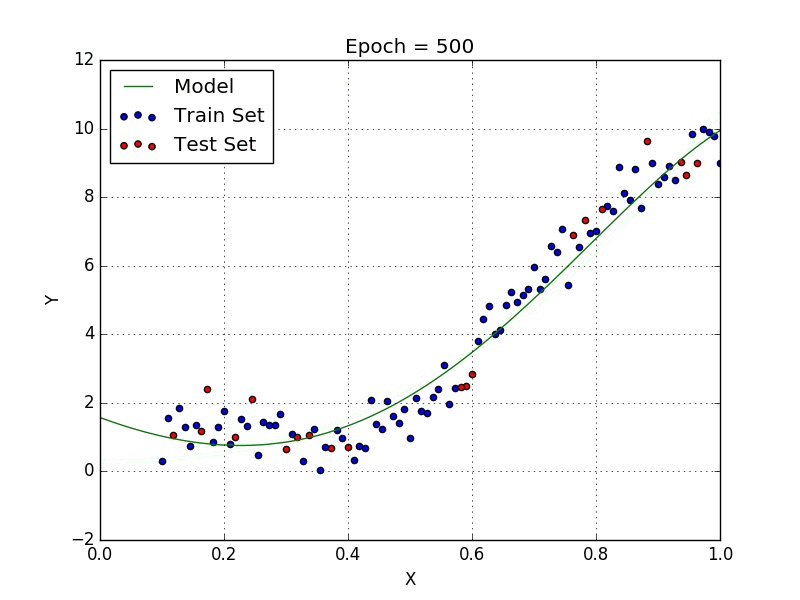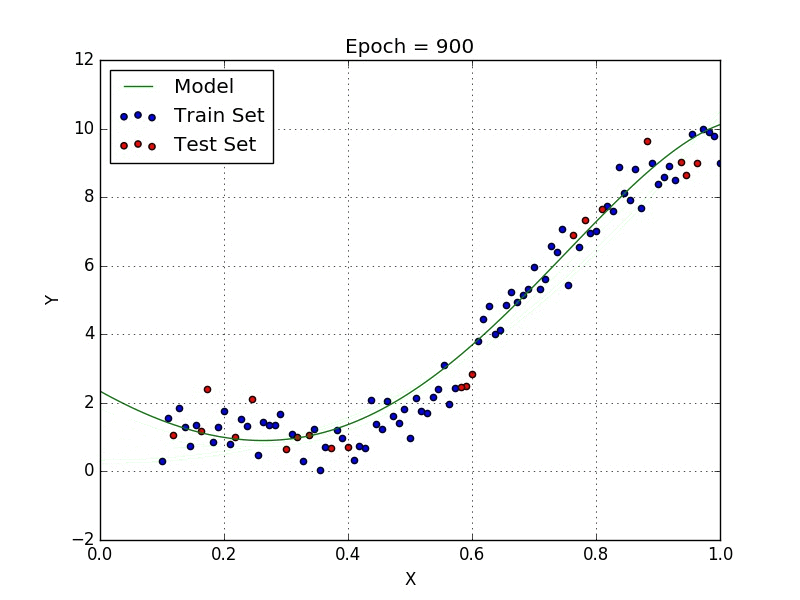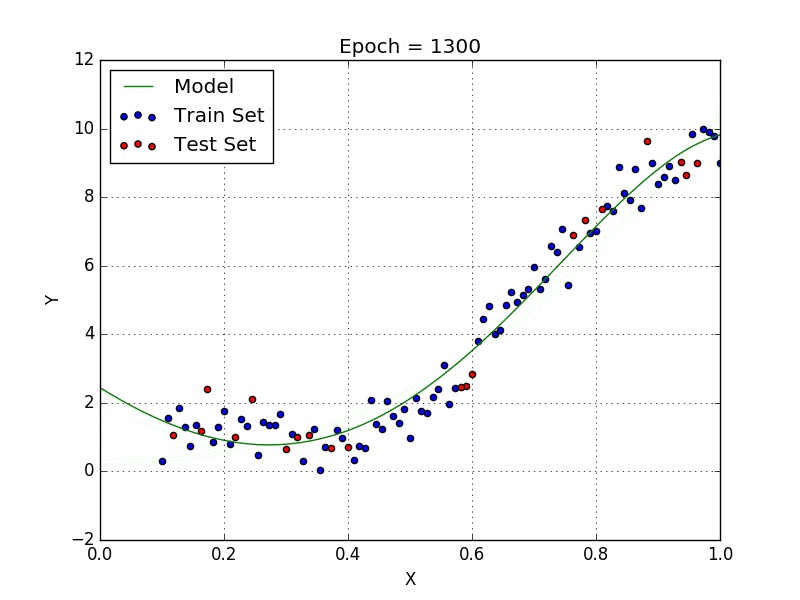
Regressione non lineare
Come si vede qui sopra, con un modello non lineare è possibile approssimare gli stessi dati in modo molto più preciso.
Inoltre in molti casi la regressione lineare diventa non solo poco precisa ma addirittura inutilizzabile, come nel caso di distribuzione circolare. Qui sotto una comparazione tra regressione lineare e non lineare per una distribuzione circolare.

Funzioni di attivazioni più in dettaglio
Ovviamente per essere utile la funzione di attivazione di una rete neurale non deve essere lineare. Una trattazione di tutte le funzioni di attivazione oggi utilizzate è al di là dello scopo di questo articolo, quindi mi limiterò a tre la le più note: quella a gradino, la sigmoide e la ReLU.
Funzione a gradino (Step Function):
La funzione più intuitiva è quella a gradino, in un certo senso più simile al funzionamento biologico. Per tutti i valori negativi la risposta rimane 0, mentre salta a +1 appena il valore raggiunge o supera anche di poco lo zero. Il vantaggio è che è semplice da calcolare, e “normalizza” i valori di output comprimendoli tutti in un range compreso tra 0 e +1.

Funzione a gradino
Tuttavia, questo tipo di funzione non è realmente impiegata per via della poca stabilità, e soprattutto perché non è differenziabile nel punto in cui cambia valore (non esistono derivate in quel punto). La derivata non è altro che la pendenza della retta tangente in quel punto (figura sotto), ed è fondamentale nel deep learning, in quanto determina la direzione verso cui orientarsi per gli aggiustamenti ai valori.

Derivata (in rosso o verde a seconda della direzione) di una funzione
In breve possiamo dire che questo cambio brusco di stato rende difficile controllare il comportamento della rete. Una piccola modifica su un peso potrebbe migliorare il comportamento per un determinato input ma farlo saltare totalmente per altri simili.
Funzione sigmoide
Per ovviare al problema fu introdotta la funzione sigmoide. Ha delle similitudini con quella a gradino, ma il passaggio da 0 a +1 è più graduale, con un andamento a forma di s appunto. Il vantaggio di questa funzione, oltre ad essere differenziabile, è di comprimere i valori in un range tra 0 e 1 e di essere quindi molto stabile anche per grosse variazioni nei valori. La sigmoide è stata molto usata per parecchio tempo, ma ha comunque i suoi problemi.
È una funzione che presenta una convergenza molto lenta, visto che per valori di ingresso molto grandi la curva è quasi piatta, con la conseguenza che la derivata tende a zero. Questa scarsa responsività verso gli estremi della curva tende a causare problemi di vanishing gradient, di cui parleremo più avanti[3]. Inoltre non essendo centrata sullo zero i valori in ogni step di learning possono essere solo tutti positivi o tutti negativi, il che rallenta il processo di training della rete.
Si tratta di una funzione quindi non più molto utilizzata nei layer intermedi, ma ancora decisamente valida in output per i compiti di categorizzazione.

Funzione ReLU
La funzione ReLU (rectifier linear unit) è una funzione divenuta ultimamente molto utilizzata, specialmente nei layer intermedi. La ragione è che si tratta di una funzione molto semplice da calcolare: appiattisce a zero la risposta a tutti i valori negativi, mentre lascia tutto invariato per valori uguali o superiori a zero.
Questa semplicità, unita al fatto di ridurre drasticamente il problema del vanishing gradient, la rende una funzione particolarmente appetibile nei layer intermedi, dove la quantità di passaggi e di calcoli è importante. Calcolare la derivata infatti è molto semplice: per tutti i valori negativi è uguale a zero, mentre per quelli positivi è uguale a 1. Nel punto angoloso nell’origine invece la derivata è indefinita ma viene comunque impostata a zero per convenzione.
Alla luce di queste due funzioni, dovrebbero diventare più chiari anche i risultati dell’esempio precedente, che per comodità riportiamo qui sotto.
Guardando di nuovo i neuroni del layer intermedio, notiamo che la loro funzione di attivazione è una ReLU, quindi nel primo caso 3.45 rimane invariato, mentre il valore del secondo da -0.45 viene schiacciato su zero. Il neurone di output invece ha una funzione sigmoide, e per un valore di 6.9 la risposta diventa praticamente uguale a 1

Le funzioni di attivazioni possibili sono numerose. ma queste in questo contesto le tre illustrate sono sufficienti a dare un’idea di cosa siano e del perché vengano usate.
Ipotizziamo di voler costruire una rete neurale in grado di riconoscere dei numeri. Per semplicità userò i classici numeri digitali, composti da 7 segmenti.
Ovviamente riconoscere numeri di questo genere non è particolarmente utile, ma servirà allo scopo di illustrare il concetto.
Nell’immagine qui sopra abbiamo una possibile rete neurale configurata per questo compito. Nello specifico ci sono 7 neuroni di input, uno per segmento, che possono assumere valori di 0 o 1, un layer nascosto con 4 neuroni attivati da ReLU, un layer di output con 10 neuroni (uno per numero decimale). Nell’immagine la rete riceve in ingresso appunto il numero 6, riconoscendolo in uscita correttamente.
Abbiamo visto come i valori di input si propagano attraverso i layer nascosti fino ai neuroni di output, ma quindi? Dov’è l’apprendimento? Come fa la rete a riconoscere il numero? L’apprendimento consiste nel regolare bias e pesi in modo da approssimare il risultato a quello voluto.
Quella illustrata nel prossimo paragrafo è una delle tecniche più utilizzate a riguardo.
Gradient Descent
Innanzitutto tutti i pesi e i valori di bias vengono inizialmente valorizzati in modo casuale, il che significa che nella prima passata la risposta della rete sarà casuale, e molto probabilmente completamente errata.
Il primo passo è calcolare (mi attengo al proposito di evitare formule) quella che viene chiamata cost function, ovvero una funzione che rappresenti in qualche modo l’errore (come differenza tra output e valore atteso) quadratico medio di tutti gli output.
Nell’esempio qua sopra una risposta corretta prevede nel layer di output un valore vicino a 1 per il neurone che rappresenta il 6, e valori prossimo allo zero per tutti gli altri, e in questo caso la Cost function sarebbe vicina allo zero, segno di un risultato corretto.
Il gradient descent è appunto una tecnica che ha lo scopo di minimizzare quanto possibile la cost function. Immaginando la cost funcion come funzione di sole due variabili (per semplificare), lo scopo del nostro gradient descent è quello di trovare il minimo globale della funzione, ovvero il punto più basso. In questo caso semplificato il minimo sembra abbastanza ovvio, ma nella maggior parte dei casi le funzioni sono molto più complesse, e bisogna arrivarci per approssimazioni successive.
Cercando di semplificare al massimo con un’analogia, tutto quello che fa il gradient descent è partire da un punto casuale, e poi in base alle derivate (vedi sopra) spostarsi in una direzione o in un’altra. Una derivata elevata significa pendenza elevata, quindi ancora lontani dal minimo, e il successivo passo sarà ampio. Una derivata piccola significa pendenza lieve, di conseguenza vicini al minimo, il che comporta passi di avvicinamento più piccoli.
Nella figura si può vedere come il gradiente si avvicini al minimo per passi successivi, riducendo l’ampiezza (che poi altro non è che il tasso di apprendimento) man mano che il fondo si fa più vicino.

Backpropagation
A tutto il discorso fatto finora manca ancora un tassello: abbiamo visto come i dati si propagano attraverso la rete, abbiamo visto la tecnica più utilizzata per ridurre l’errore (di fatto apprendere). Appurato che alla fine si tratta di “riaggiustare” i pesi, e che farlo a mano è fuori discussione, come si fa? È qui che interviene la backpropagation, ovvero la propagazione “all’indietro” dell’errore[4].
Quello che succede in sintesi è che una volta calcolata la nostra Cost Function, abbiamo un’idea abbastanza precisa di quanto ciascun neurone di output sia lontano dal proprio valore atteso, e in che direzione (positiva o negativa).
Se il risultato atteso è 6, ci aspettiamo 1 nel neurone 6 e 0 in tutti gli altri. Se il neurone 6 presenta 0.7, allora la correzione da fare è 0.3 e riarrangeremo i pesi delle connessioni a quel neurone in modo da produrre complessivamente un valore leggermente più grande.
Se il neurone 4 invece di 0 presenta 0.8 allora la correzione sarà -0.8 e si riarrangeranno le connessioni a questo neurone in modo da abbassarne drasticamente l’output. Questo viene effettuato dall’algoritmo calcolando le derivate e moltiplicando opportunamente le matrici di valori e pesi.
Deep Learning
Infine due parole sul concetto di deep learning, che è un caso specifico di machine learning in generale.
Il termine viene dal fatto che per questa tecnica si utilizzano reti neurali “deep”, ovvero profonde diversi layer. Lo scopo di avere diversi layer invece che uno solo è che per come funziona l’algoritmo, ciascun layer “generalizza” un po’ di più rispetto al precedente.
Quindi per esempio nel caso del riconoscimento delle forme geometriche, il primo riconoscerà solamente i singoli pixel, il secondo “generalizzerà” i bordi, il terzo inizierà a riconoscere forme semplici, e così via.
Conclusioni
Scopo di questo articolo era di preparare la strada a futuri approfondimenti sui vari modelli di rete neurale, dando un’idea intuitiva di cosa sono, e di come funziona a grandi linee il deep learning.
Note
1. In realtà non tutti i modelli prevedono connessioni a tutti i neuroni successivi.
2. Lo scopo dei modelli di regressione è quello di trovare un’equazione (rappresentata da un tracciato sul grafico) che rappresenti i dati in modo abbastanza preciso da spiegare il comportamento, ma anche sufficientemente “flessibile” da consentire di fare previsioni. Ad esempio nel caso di due variabili, con una regressione corretta è possibile “prevedere” il valore di un punto sull’asse Y dato il valore sull’asse X, semplicemente posizionandolo sulla retta (o curva) di regressione. La previsione sarà tanto più precisa tanto più corretta è l’equazione trovata.
3. In sostanza il problema è dovuto al fatto che la derivata della funzione si riduce a ogni passaggio, quindi reti con molti layer tendono a far “sfumare” il gradiente, rallentando di molto la convergenza.
4. Per “errore” intendiamo la differenza tra output e valore atteso.
LINKS
Neural Networks and Deep Learning
ReLU and Softmax Activation Functions
Fully Convolutional Networks for Semantic Segmentation
Activation functions and it’s types-Which is better?
10 misconceptions about Neural Networks
Generative Adversarial Networks (GANs)


