

Quali reali opportunità si presentano alle aziende con l’avvento dei modelli di fondazione (foundation models) e dell’intelligenza artificiale generativa (GenAI)? Come si determina la struttura dei costi da considerare? Quali i rischi operativi, legali ed etici? Dopo avere sperimentato i principali LLM, Spindox propone oggi un framework robusto e articolato.
Quando si parla di modelli di fondazione (foundation models) e di intelligenza artificiale generativa (GenAI), non è esagerato definire «dirompente» lo scenario davanti ai nostri occhi. Con una rapidità mai vista in passato, si stanno mettendo a punto tecnologie capaci di trasformare profondamente il modo di progettare, produrre e fare business in tutti i principali comparti dell’industria e dei servizi. Prima ancora, sta già cambiando il modo di lavorare delle persone e di contribuire al valore delle organizzazioni con le proprie capacità individuali.
Ma come devono comportarsi le aziende, in questa fase? È il caso di avventurarsi senza indugi in acque inesplorate, perché domani sarà già tardi? O è meglio, per il momento, restare spettatori e limitarsi a capire? Certo qualcuno dirà che, in questa fase, capire è già tanto. Il ruolo di Spindox, accanto alle aziende, non può che essere quello di stare un passo avanti, sperimentare e costruire i razionali in base ai quali compiere le scelte giuste. In attesa di avere tutte le risposte, occorre formulare le domande giuste. E per noi le domande giuste sono tre:
- Quali sono le reali opportunità offerte dai modelli di fondazione e dall’intelligenza artificiale generativa?
- Volendo avviare un progetto pilota in questo ambito, come se ne determina la struttura dei costi?
- Quali rischi operativi, legali ed etici devono essere considerati?
Di seguito proviamo a illustrare lo stato dei ragionamenti che stiamo facendo in Spindox, insieme ad alcuni clienti, per poi descrivere il framework operativo messo a punto per lanciare in sicurezza i primi progetti. Ma, prima di tutto, cerchiamo ci chiarire di che cosa stiamo parlando.
Che cos’è un foundation model
Con l’espressione foundation model (modello di fondazione) ci riferiamo a modelli addestrati su un ampio insieme di dati non etichettati che possono essere utilizzati per compiti diversi, con una messa a punto minima. Possono costituire la base per molte applicazioni di intelligenza artificiale. L’aspetto saliente dei modelli di questo tipo è che, attraverso l’apprendimento auto-supervisionato e un successivo lavoro di raffinamento, possono applicare le informazioni apprese in generale a un compito specifico. Questo perché i foundation model correnti sono stati addestrati a gestire il linguaggio naturale e rappresentarlo con una logica del tutto simile a quella di un essere umano.
Abbiamo dunque a che fare con un machine learning molto evoluto, che rimanda al concetto di intelligenza artificiale generale. Mentre la cosiddetta «narrow AI» si concentra su un singolo compito ed è limitata da vincoli che le impediscono di risolvere problemi sconosciuti, la «general AI» è in grado di svolgere un'ampia gamma di compiti, esibendo comportamenti che simulano le capacità cognitive umane. Si tratta di un grande passo avanti nell’ambito del famoso imitation game di Alan Turing.
Che cos’è l’intelligenza artificiale generativa
I modelli di fondazione sono il cuore dell’intelligenza artificiale generativa (GenAI), che usa reti neurali per apprendere modelli. La rete neurale viene addestrata su un ampio set di esempi e in seguito può generare nuovi dati simili al set di addestramento. In sostanza, la GenAI è un tipo di intelligenza artificiale in grado di generare nuovi contenuti, come immagini, musica, testi o ambienti virtuali, apprendendo modelli dai dati esistenti. Le architetture utilizzate sono quelle di tipo transformer (per il linguaggio naturale) e GAN (per le immagini). Altri modelli usati per la generazione delle immagini sono il Variational Autoencoder (VAE) e il Diffusion Model. Fra le tecnologie di GenAI oggi più popolari, suscitano grande interesse quelle di OpenAI (GPT, DALL-E e Whisper), ma anche Stable Diffusion di Stability, RETRO di DeepMind, DEEPCTL di Google e LLaMA di Meta.
È bene poi precisare che non tutte le tecnologie sopra menzionate sono classificabili come modelli linguistici artificiali (Large Language Model, LLM). Per esempio, Midjourney, Stable Diffusion e DALL-E non dispongono di un modello linguistico sottostante, per cui non appartengono al sottoinsieme dei LLM. In generale, un modello linguistico artificiale è definibile come una distribuzione di probabilità su sequenze di parole: data una qualsiasi sequenza di parole di lunghezza m, un modello linguistico assegna una probabilità P all'intera sequenza.
Quando poi un LLM è capace di gestire input multimodali, ovvero di elaborare sia testi (traduzione, modellazione del linguaggio), sia immagini (rilevamento di oggetti, classificazione di immagini) sia audio (riconoscimento vocale), allora andrebbe più correttamente definito come Large Multimodal Model (LMM). È il caso di GPT-4V di OpenAI, che costituisce appunto l’evoluzione multimodale di GPT-4.0, essendo in grado di elaborare sia dati testuali sia immagini. Ad esempio, può accettare un'immagine come parte di un prompt e fornire una risposta testuale appropriata.
Non c’è solo ChatGPT
Oggi l’attenzione del grande pubblico si concentra su ChatGPT (il chatbot di OpenAI addestrato con GPT) e su Midjourney. Entrambi i sistemi sono accessibili gratuitamente o a un prezzo relativamente modesto e utilizzati per la generazione di testi e immagini. Tuttavia, al di là di queste due applicazioni, il mondo dell’intelligenza artificiale generativa è molto più vasto. E, pensando a soluzioni verticali per il business, occorre immaginare architetture complesse. Per quanto ne costituiscano il cuore, i modelli di fondazione rappresentano solo una parte di tali architetture. Uno schema generale di architettura per l’impiego della GenAI in un contesto enterprise potrebbe essere quello rappresentato nel disegno 1, che proponiamo qui sotto:
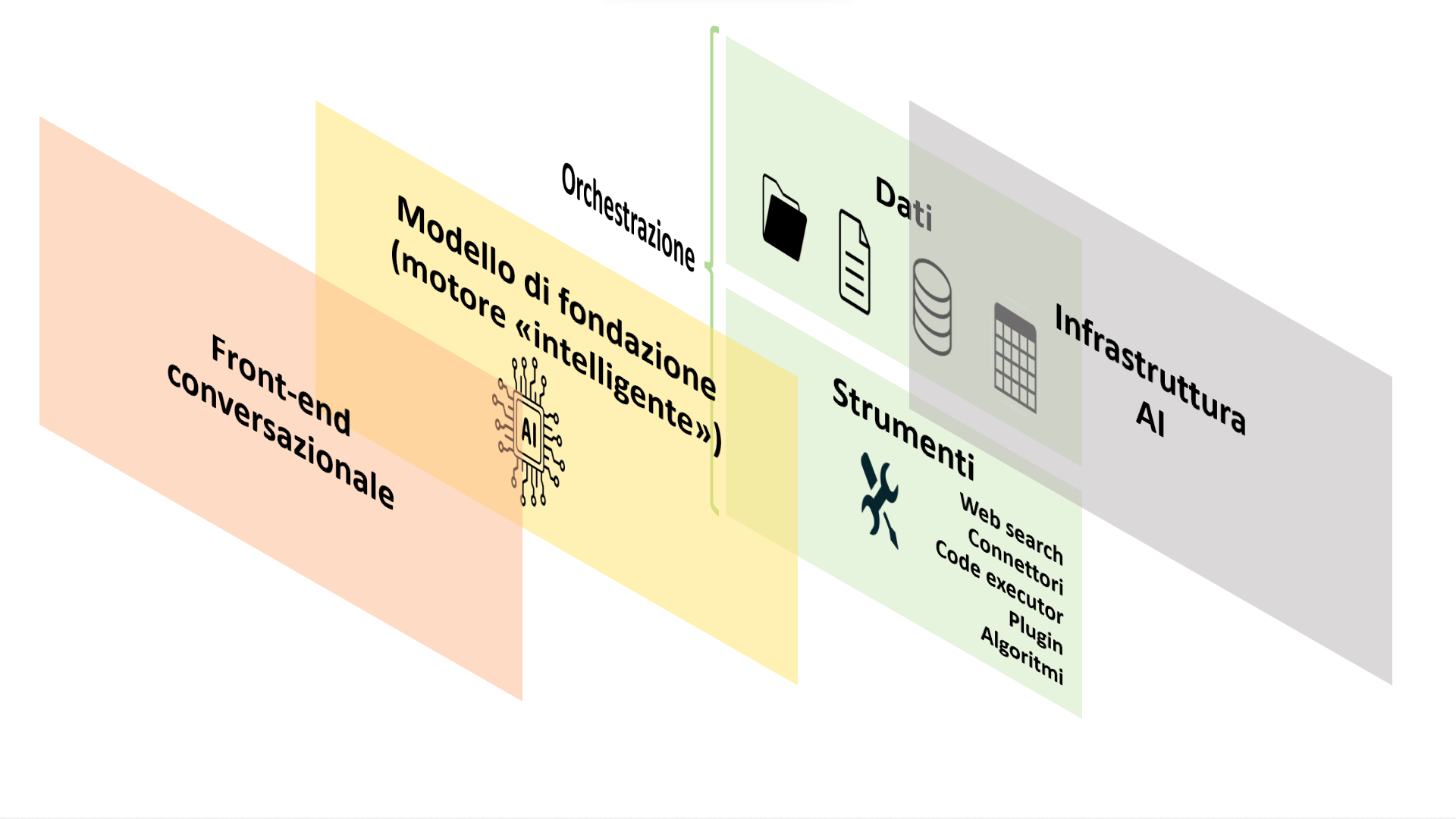

Modello semplificato di architettura entreprise per intelligenza artificiale generativa.
Lo strato colorato in verde corrisponde alla funzione di orchestrazione, che agisce in realtà a due livelli: da un lato tra il modello di fondazione e il front-end, dall’altro lato fra il modello stesso e le applicazioni. Il tutto deve essere poi inquadrato nel contesto di un’infrastruttura AI, come Azure OpenAI Service, Amazon Forecast o Google Cloud AI.
Particolare rilevanza hanno, in uno schema di questo tipo, funzioni come il prompt filtering (che impedisce, in entrata e in uscita, il passaggio di messaggi inappropriati), il metaprompting (ovvero la creazione di un prompt attraverso un altro prompt) e il data grounding (l’utilizzo di set di dati, documenti, reti e database esterni per fondare il modello su dati reali e sul contesto dell’utente, come spieghiamo meglio più avanti).
La gestione di tutto ciò è facilitata oggi – o, per meglio dire, guidata – da framework e pattern architetturali. È il caso di Copilot Stack, la cui espansione verso l’AI è stata presentata da Microsoft a maggio 2023.
GenAI: quali opportunità per aziende
Ciò che colpisce, quando si parla di intelligenza artificiale generativa, è la straordinaria velocità con cui essa procede nel cammino verso la maturità tecnologica. Tuttavia, Gartner ci insegna che la maturità tecnologica non conduce in modo deterministico al plateau della produttività. È dunque importante distinguere fra prospettive di breve-lungo termine, più o meno fantasiose, e opportunità di breve termine. Ogni ragionamento deve essere supportato da un business case robusto e misurabile.
Spindox ritiene che le opportunità per le aziende legate alla GenAI si concentrino oggi in tre aree legate all’ambito del Natural Language Processing (NLP):
- Efficientamento del processo di software development (design, coding e testing)
- Sviluppo di applicazioni verticali (chatbot e voicebot, sentiment analysis, ricerca all’interno di corpora testuali, parafrasi di documenti esistenti o generazione di testi originali)
- Supporto al project management (produzione di presentazioni, report ecc.)
È verso queste tre aree che abbiamo indirizzato i nostri sforzi di ricerca per realizzare primi progetti-pilota, anche in collaborazione con quei clienti che hanno deciso di muoversi subito. In parallelo, riconosciamo l’esistenza di alcune sfide da indirizzare, alle quali corrispondono altrettanti fattori critici di successo.
Prima sfida: accrescere l’affidabilità dell’output
La prima sfida riguarda l’esigenza di garantire un’adeguata qualità dell’output. Quando usiamo ChatGPT, siamo avvisati da OpenAI che le informazioni fornite potrebbero non essere complete o accurate e che la stessa OpenAI non si assume la responsabilità di verificarne la veridicità. Com’è ovvio, una cosa simile sarebbe inaccettabile in ambito enterprise. Per questo occorre che, quando si realizzano applicazioni verticali pensate per risolvere specifici problemi di business, i modelli di fondazione siano parte di un processo di data grounding, ossia nutriti con dati di qualità, accurati e specifici, non compresi nel dataset impiegato nella fase di training degli stessi modelli. Il rischio delle cosiddette «allucinazioni» dell’algoritmo è sempre in agguato.
L’approccio RAG (Retrieval Augmented Generation) è quello oggi più riconosciuto. Si tratta di un metodo che combina un componente di ricerca («information retrieval») con un LLM. Per formulare le risposte al prompt, il modello linguistico accede a una fonte esterna di conoscenza, più ampia di quella su cui è stato addestrato e contestualizzata in termini cronologici (pensiamo, per esempio, che GPT si ferma al 2021) o di dominio (GPT è generalista). RAG riceve un input e recupera un insieme di documenti pertinenti. Questi sono concatenati con la richiesta originale di input e inviati al generatore di testo che produce l'output finale.
L’approccio RAG è implementato in Google Search Generation Experience, che integra due modelli linguistici «retrieval-enhanced» (REALM della stessa Google e il già citato RETRO di DeepMind) con il sistema di retro-fitting RARR. Ma uno schema simile è adottato da Microsoft, che ha integrato GPT con il suo motore di ricerca Bing. C’è poi il caso del plugin per ChatGPT realizzato da AIPRM, che dà accesso a una libreria di modelli di prompt predefiniti e selezionati.
Una strategia complementare di data grounding consiste nell’aggiunta di una prospettiva determinista all’approccio squisitamente probabilistico della rete neurale. In quest’ottica Spindox ritiene particolarmente interessante il modello LMQL, messo a punto da ETH Zürich (ne abbiamo parlato in LMQL: dal prompt engineering al language model programming, 14 luglio 2023).
Seconda sfida: ottimizzare il costo dell’hardware
Non meno rilevante è la seconda sfida, che riguarda il costo delle risorse hardware e la loro ottimizzazione. L’intelligenza artificiale generativa richiede grandi capacità di calcolo e quindi rischia di non essere sostenibile, sia sul piano economico sia dal punto di vista ambientale. Del problema ci siamo occupati recentemente in un altro articolo sul blog di Spindox (L’intelligenza artificiale ha fame di energia, 14 ottobre 2023). A parte lo sviluppo di chip di nuova concezione – come le tensor processing unit (TPU), sulle quali un vendor come Google sta puntando in alternativa alle più tradizionali GPU (lo abbiamo spiegato qui) – è importante lavorare sull’ottimizzazione dei modelli stessi. L’obiettivo è ridurre al minimo il numero di parametri, senza perdere in accuratezza dell’output.
Peraltro, i costi computazionali dei grandi modelli linguistici artificiali si riflettono sui prezzi praticati dai fornitori «as-a-service» di questo tipo di tecnologia. Sappiamo, per dire, che OpenAI pratica un modello di pricing per token (750 parole corrispondono più o meno a 1.000 token). Per l’utilizzo di GPT-4.0, la tariffa attuale è pari a 0,03 dollari per 1.000 token. Sembra un’inezia, eppure basta poco per ritrovarsi con una bolletta di migliaia di dollari al mese. Soprattutto, si tratta di un costo che può subire una brusca impennata, a fronte di un significativo incremento nell’utilizzo del sistema. Possono essere valutati scenari alternativi, basati sull’hosting del LLM in un cloud pubblico, che di volta in volta si rivelano più o meno convenienti. Per esempio, l’hosting di LLaMA-2 7B nell’infrastruttura di AWS, che richiede almeno un’istanza di EC2 g5.2xlarge, nonché l’impiego di AWS API Gateway e AWS Lambda, può essere più economico rispetto a GPT-4.0. A patto che le performance di LLaMA-2 7B, che ha «solo» sette miliardi di parametri, siano sufficienti rispetto al caso d’uso che dobbiamo gestire. Perché, se viceversa optiamo per LLaMA-2 13B (tredici miliardi di parametri), i costi di hosting rischiano di triplicare.
Terza sfida: la protezione dei dati
Vi è infine una questione di natura non tecnica, ma di grande rilevanza, che riguarda la tutela dei dati personali o sensibili. L’uso dei modelli di fondazione, e in particolare dei LLM, implica in genere l’integrazione fra tecnologie open source e soluzioni commerciali. Le conseguenze, dal punto di vista della protezione dei dati, sono evidenti. Il caso d’uso più facile da immaginare è quello in cui l’organizzazione dà in pasto al modello «aperto», magari accessibile via API, informazioni che hanno natura riservata: dati dell’azienda, dei propri dipendenti o del cliente. Ovviamente si tratta di uno scenario da evitare in ogni modo, anche attraverso la definizione di specifiche policy e la formazione di tutte le persone coinvolte.
Che cosa sta facendo Spindox nell’ambito della GenAI
Da anni il nostro gruppo lavora nel campo delle tecnologie per il trattamento del linguaggio naturale (NLP), per cui oggi può contare su un’esperienza molto significativa, maturata in ambiti applicativi eterogenei, da applicare al mondo dei modelli di fondazione e dei LLM. Spindox ha così messo a punto un framework ad hoc, che lavora su sei componenti principali: 1. pipeline di data processing (gestione del flusso di dati e indicizzazione); 2. memoria (miglioramento delle performance mediante l’uso di strategie RAG, database vettoriali, knowledge graph ecc.); 3. raffinamento del LLM; 4. LLM-Ops (standardizzazione delle operazioni in produzione, compresa la definizione di template di prompt engineering); 5. orchestrazione multi-agente (per la soluzione di compiti che richiedono l’esecuzione di più agenti LLM-based); 6. API gateway (integrazione con le fonti dati e disegno dell’interfaccia utente).
Il tutto è schematizzato nella figura 2, qui sotto:
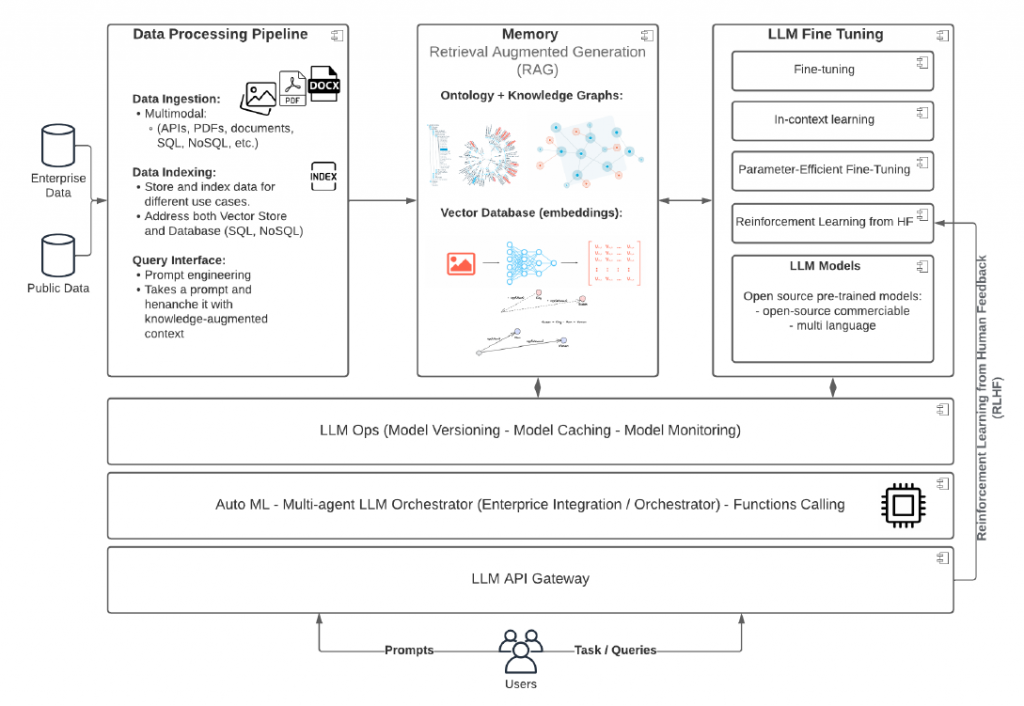
Figura 2: Framework Spindox per l’industrializzazione dei LLM.
Grazie a questo framework robusto e articolato, oggi Spindox è in grado di:
- impiegare tutti i principali LLM, commerciali e open-source, valutando pregi e difetti di ciascuna soluzione;
- implementare e industrializzare processi abilitati da LLM, sia on premise sia in modalità a servizio, garantendo la privacy e la protezione intellettuale dei dati del cliente;
- definire modelli ad hoc per personalizzare il prompt engineering in funzione del contesto del cliente, di compiti specifici da eseguire e di dati particolari che devono essere processati;
- gestire la memoria del sistema e la base di conoscenza in modo strutturato, in modo da superare i limiti degli LLM in termini di numero di token e di efficienza computazionale, a tutto vantaggio dei costi;
- costruire flussi decisionali e operativi complessi, nei quali diversi agenti basati su LLM operano contemporaneamente e collaborano per il raggiungimento di obiettivi condivisi;
- lavorare con modelli multimodali, che integrano il trattamento del linguaggio naturale con quello di contenuti di altro tipo (immagini, filmati, audio);
- superare il problema delle allucinazioni degli LLM pre-addestrati, attraverso l’approccio GAM e l’impiego di LMQL precedentemente descritti.
Approfondimenti
Simon Attard, Grounding Generative AI, Medium, marzo 2022: https://medium.com/@simon_attard/grounding-large-language-models-generative-ai-526bc4404c28.
Sebastian Borgeaud e altri, Improving language models by retrieving from trillions of tokens, Arxiv, 8 dicembre 2021 (v1) - 7 febbraio 2022 v3: https://arxiv.org/abs/2112.04426.
Luyo Gao e altri, RARR: Researching and Revising What Language Models Say, Using Language Models, Arxiv, 17 ottobre 2022 (v1) - 31 maggio 2023 (v3): https://arxiv.org/abs/2210.08726.
Kelvin Guu, REALM: Retrieval-Augmented Language Model Pre-Training, Arxiv, 10 febbraio 2020: https://arxiv.org/abs/2002.08909.


